GPT-5.5와 Claude Opus 4.7은 둘 다 “에이전틱 코딩 최강”을 내세우며 2026년 4월에 일주일 간격으로 출시됐습니다. Anthropic은 4월 16일, OpenAI는 4월 23일. 강점을 같은 영역에서 주장하는 두 모델 중 어떤 쪽이 실제로 앞서 있는지 항목별로 비교했습니다.
목차
GPT-5.5 vs Claude Opus 4.7 공통점 — 둘 다 1M 토큰 컨텍스트
GPT-5.5와 Claude Opus 4.7은 모두 1M 토큰 컨텍스트 윈도우를 지원합니다. 긴 문서, 대규모 코드베이스, 방대한 데이터를 통째로 입력해 작업할 수 있다는 점에서 동일합니다. 두 모델 모두 추론 기반 아키텍처를 사용하며 에이전틱 멀티 단계 작업을 주요 목표로 설계됐습니다.
출발점이 같으니 갈리는 지점이 선택의 핵심입니다.
코딩 벤치마크 비교
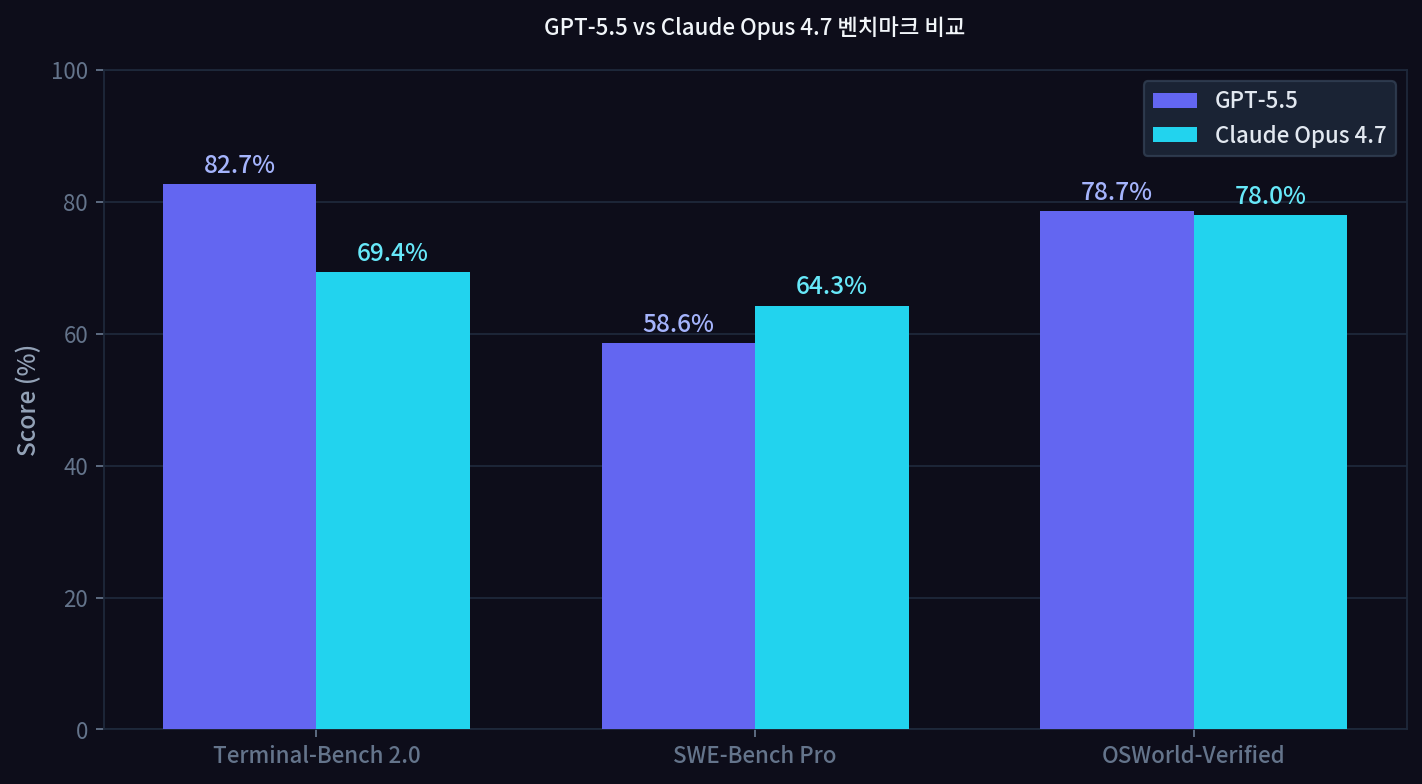
| 벤치마크 | GPT-5.5 | Claude Opus 4.7 | 우세 |
|---|---|---|---|
| Terminal-Bench 2.0 | 82.7% | 69.4% | GPT-5.5 |
| SWE-Bench Pro | 58.6% | 64.3% | Opus 4.7 |
| SWE-Bench Verified | — | 87.6% | Opus 4.7 |
| OSWorld-Verified | 78.7% | 78.0% | GPT-5.5 |
코딩 결과는 하나의 모델이 압도하는 구도가 아닙니다. 터미널 기반의 장기 실행 작업에서는 GPT-5.5가 크게 앞서고 코드 제출·리뷰 방식의 SWE-Bench에서는 Opus 4.7이 우위입니다.
Terminal-Bench 2.0은 터미널 명령어를 반복 실행하며 복잡한 작업을 끝까지 완수하는 능력을 측정합니다. 여기서 GPT-5.5의 82.7%는 현재 공개 모델 중 최고 점수입니다.
SWE-Bench Pro는 실제 오픈소스 저장소의 이슈를 코드로 해결하는 방식으로 평가합니다. Opus 4.7의 64.3% 대 GPT-5.5의 58.6%는 ‘마무리 품질’에서 Claude가 앞선다는 의미로 해석할 수 있습니다.
추론·지식 벤치마크
추론 영역에서는 Opus 4.7이 대체로 앞섭니다. GPQA(박사급 과학 문항), HLE(고난도 논리 추론), FinanceAgent(금융 에이전트 작업)에서 Opus 4.7이 높은 점수를 보였습니다.
반면 BrowseComp(웹 탐색 기반 정보 수집)와 CyberGym(보안 과제 해결)에서는 GPT-5.5가 앞섭니다.
전체적으로 보면 Opus 4.7은 깊은 추론과 정확한 지식 회수가 중요한 작업에 강하고 GPT-5.5는 도구를 반복적으로 호출하며 장시간 실행되는 에이전틱 작업에 강합니다.
멀티모달 처리 방식 차이
두 모델의 가장 큰 구조적 차이입니다.
GPT-5.5는 텍스트, 이미지, 오디오, 영상을 단일 통합 시스템으로 처리하는 네이티브 옴니모달 구조입니다. 음성으로 질문하면서 이미지를 함께 첨부하면 별도 변환 단계 없이 두 입력이 동시에 처리됩니다.
Claude Opus 4.7은 텍스트와 이미지를 처리하며, 이미지 해상도 면에서는 긴 쪽 기준 최대 2,576픽셀까지 지원합니다. 이전 Claude 모델 대비 세 배 이상 높아진 수치로 고해상도 이미지 분석에서 강점을 보입니다. 다만 오디오와 영상 직접 처리는 지원하지 않습니다.
음성 입력이나 영상 분석이 핵심인 파이프라인이라면 GPT-5.5 쪽으로 기울 수밖에 없습니다. 고해상도 이미지 분석 중심이라면 Opus 4.7도 충분히 경쟁력이 있습니다.
가격 비교
| 모델 | 입력 (1M 토큰) | 출력 (1M 토큰) |
|---|---|---|
| Claude Opus 4.7 | $5 | $25 |
| GPT-5.5 | $5 | $30 |
| GPT-5.5 Pro | $30 | $180 |
입력 가격은 동일하지만 출력에서 차이가 납니다. Opus 4.7이 출력 기준 약 17% 저렴합니다. 대량 출력이 필요한 배치 작업이나 반복 파이프라인을 운영한다면 이 차이가 비용에 상당히 누적됩니다.
Claude Opus 4.7은 프롬프트 캐싱으로 최대 90% 비용 절감이 가능하고 배치 처리 시 50% 절감이 적용됩니다. API 비용을 최소화하면서 고품질 추론이 필요한 경우 Opus 4.7 쪽이 경제적입니다.
Claude Opus 4.7만의 기능 — xhigh 추론과 ultrareview
Opus 4.7에는 새로운 추론 강도 옵션 xhigh가 추가됐습니다. 기존 high와 max 사이에 위치하며 추론 깊이와 응답 속도를 더 세밀하게 조정할 수 있습니다. 복잡도가 다른 여러 작업을 다루는 팀에서 비용 대비 성능을 최적화할 때 유용합니다.
Claude Code에 추가된 ultrareview 커맨드는 버그 탐지 특화 코드 리뷰 기능입니다. 코드 품질 리뷰 워크플로우를 자동화하려는 개발팀에게 실질적인 도구입니다.
어떤 상황에 어떤 모델이 맞을까요
GPT-5.5가 더 나은 경우
– 터미널 명령어를 반복 실행하며 작업을 완수하는 자율 에이전트 구성
– 오디오·영상 입력이 포함된 멀티모달 파이프라인
– 컴퓨터 화면을 직접 제어하며 GUI 작업을 자동화하는 경우
– ChatGPT Plus 구독 중으로 추가 비용 없이 최신 모델을 쓰고 싶은 경우
Claude Opus 4.7이 더 나은 경우
– 코드 제출·리뷰 품질이 중요한 소프트웨어 개발 (SWE-Bench Pro 우세)
– 박사 수준의 깊은 추론이 필요한 과학·금융 분야 작업
– API 출력 토큰 비용을 절감해야 하는 대규모 파이프라인
– 고해상도 이미지 분석 중심의 비전 작업
직접 비교해 보는 것이 가장 좋습니다
두 모델 모두 구독 범위 내에서 바로 사용할 수 있습니다. GPT-5.5는 ChatGPT Plus($20/월) 이상에서, Claude Opus 4.7은 Claude Pro($20/월) 이상에서 접근 가능합니다. 벤치마크 수치는 참고 기준이지만 본인의 실제 작업에서 어떻게 동작하는지가 더 중요합니다.
같은 작업을 두 모델에 각각 입력해 결과를 비교하는 것이 가장 확실한 판단 방법입니다. GPT-5.5의 출시 배경과 플랜별 가격은 GPT-5.5 완전 정리에서 더 자세히 확인하실 수 있습니다.
참고: BenchLM.ai 비교 | Anthropic Claude Opus 4.7 소개 | OpenAI GPT-5.5 소개