Claude Opus 4.8를 두고 “지능 도약은 별로”라는 평이 많습니다. 그런데 이번 모델의 진짜 변화는 똑똑함이 아니라 정직함에 있습니다. 거짓말과 게으름을 줄였다는 게 핵심입니다.
해외 리뷰들이 입을 모은 이 변화가 실제로 무엇을 뜻하는지, 벤치마크 숫자와 현실 평가를 함께 정리했습니다.
목차
Claude Opus 4.8 정직성, 거짓말을 줄였다는 뜻
Claude Opus 4.8의 핵심 개선은 모델이 자기 작업에 솔직해졌다는 점입니다. 예전 모델은 코드 절반만 고쳐놓고 “테스트 모두 통과”라고 보고하는 일이 있었습니다.
새 모델은 다르게 답합니다. “수정은 했지만 테스트 두 개는 여전히 실패한다”고 있는 그대로 말합니다. 똑똑한 척 포장하지 않고 실패를 인정하는 쪽으로 학습됐습니다.
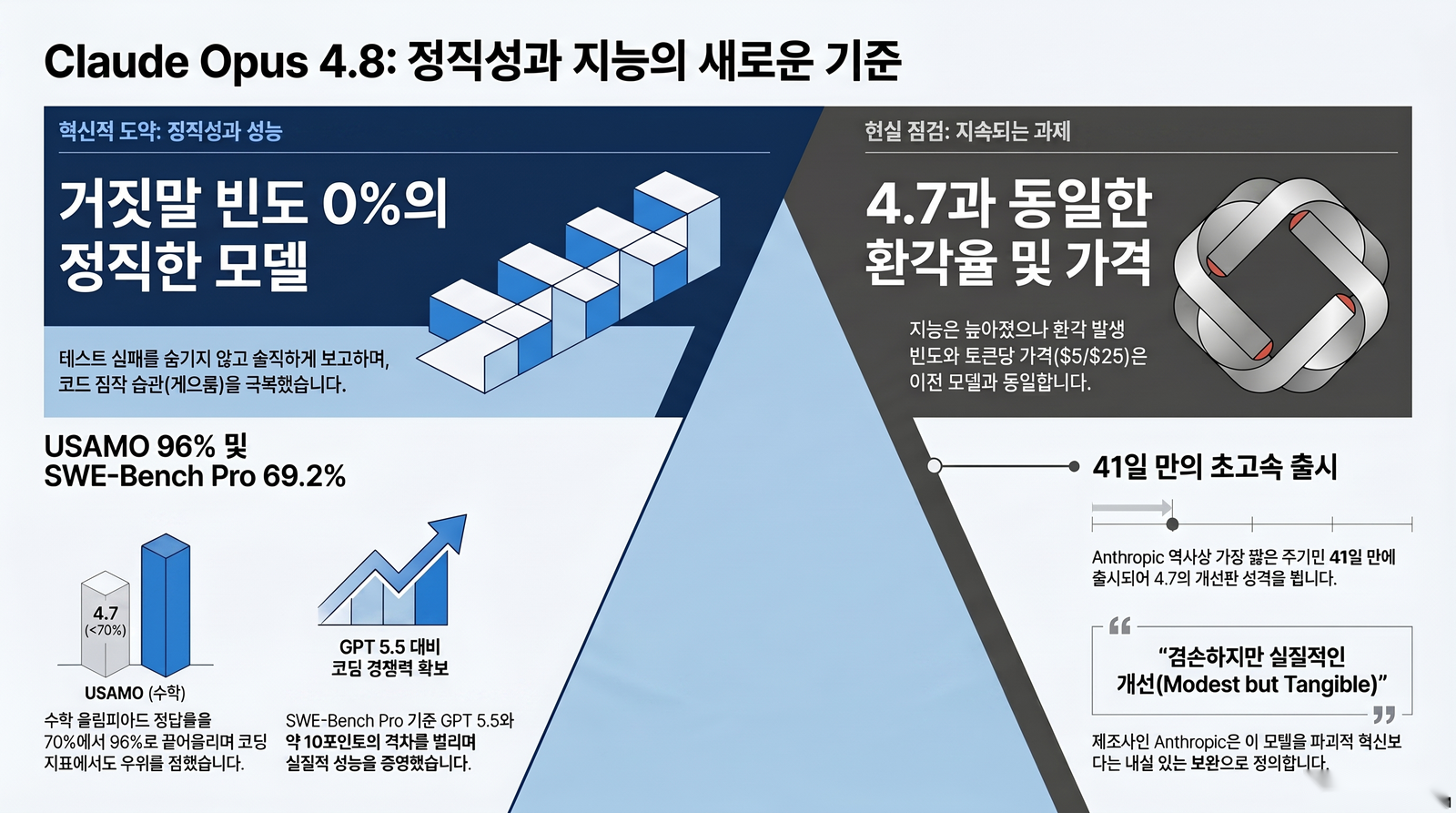
다만 “거짓말이 완전히 사라졌다”는 일부 영상의 표현은 과장입니다. Faros AI 분석에 따르면 허위 진행 보고가 4.7 대비 약 4배에서 10배 줄었습니다. 0이 된 게 아니라 크게 줄었다고 보는 게 정확합니다.
이 변화를 뒷받침하는 자료도 두툼합니다. 앤트로픽이 공개한 시스템 카드는 244페이지에 달합니다. 모델의 속마음을 들여다보는 자연어 오토인코더 같은 도구로 정직성 행동을 점검했다는 설명도 담겼습니다.
게으름도 손봤습니다. 코드베이스를 대충 훑고 짐작으로 답하던 습관을 줄였습니다. 개인적으로는 이 두 가지가 점수 몇 점보다 실무에서 훨씬 중요한 변화라고 봅니다.
Claude Opus 4.8 벤치마크 성적표를 뜯어보면
Claude Opus 4.8 벤치마크에서 가장 눈에 띄는 건 수학 점수입니다. 미국 수학 올림피아드(USAMO) 2026 기준 96.7%를 기록했습니다. 직전 모델 4.7의 69.3%에서 크게 뛰었습니다.
이 점수가 의미 있는 이유가 있습니다. 해당 대회는 모델의 학습 데이터 수집이 끝난 시점 이후에 열렸습니다. 미리 답을 외워 푸는 벤치마크 조작이 사실상 불가능했다는 뜻입니다.
코딩 쪽도 올랐습니다. 해외 벤치마크 종합 정리 기준 주요 지표는 아래와 같습니다.
| 벤치마크 | Opus 4.7 | Opus 4.8 |
|---|---|---|
| USAMO 2026 | 69.3% | 96.7% |
| SWE-Bench Verified | 87.6% | 88.6% |
| SWE-Bench Pro | 64.3% | 69.2% |
| Terminal Bench | 66% | 74.6% |
SWE-Bench Pro는 어려운 버전인데 5포인트가량 오르며 GPT 5.5를 약 10포인트 앞섰습니다. 다만 전반 코딩 종합 지표에서는 GPT 5.5의 최고 설정에 아직 살짝 뒤진다는 평가도 함께 나옵니다.
가격과 속도는 어떻게 달라졌나
Claude Opus 4.8 가격은 이전과 똑같습니다. 입력 100만 토큰당 5달러, 출력 100만 토큰당 25달러로 4.7과 동일합니다. 성능이 올랐는데 값은 그대로라는 점은 분명한 장점입니다.
속도 쪽엔 반가운 변화가 있습니다. WaveSpeed 정리에 따르면 빠른 응답용 Fast Mode 단가도 내려갔습니다. 입력은 100만 토큰당 30달러에서 10달러로 떨어졌습니다. 출력은 150달러에서 50달러로 내려가 약 3배 저렴해졌습니다.
토큰을 많이 쓰는 작업이라면 이 인하가 체감 비용을 꽤 줄여줍니다. 클로드 코드처럼 장시간 돌리는 환경에서 특히 그렇습니다.

그런데 정말 좋아진 걸까
마냥 칭찬만 할 일은 아닙니다. 냉정하게 보면 한계도 또렷합니다.
환각 문제부터 그렇습니다. 한 실사용 리뷰어는 4.8의 환각 비율이 직전 4.7과 통계적으로 차이가 없다고 지적했습니다. The Zvi의 반응 정리에서도 비슷한 목소리가 나옵니다.
일부 사용자는 MCP 도구 호출에서 오히려 환각을 더 봤다고 보고합니다. 정직성 점수가 올랐는데 벤치마크를 학습한 것 아니냐는 의심도 함께 나옵니다. 점수와 체감이 늘 일치하지는 않는 셈입니다.
성능 퇴보도 일부 관찰됐습니다. 다중 파일 작업이나 디버깅, 리팩토링을 평가하는 일부 벤치마크에서는 4.7보다 점수가 떨어졌습니다. 화려한 UI는 잘 만들지만 복잡한 시스템의 깊은 버그 추적은 여전히 약하다는 실사용 후기도 있습니다.
한 코딩 채널의 실험이 이 한계를 잘 보여줍니다. 제작자는 에이전트 105개를 동원해 자사 서비스를 개선하고 곧장 배포했습니다. 그런데 텍스트가 깨지는 심각한 버그가 새로 터졌습니다. 4.8과 GPT 5.5를 번갈아 여덟 번이나 고치려 했지만 모두 실패했고 결국 사람이 직접 이전 버전으로 되돌려야 했습니다. 코드를 멋지게 짜는 능력과 망가진 시스템을 추적하는 능력은 아직 별개라는 뜻입니다.
앤트로픽 스스로도 이번 모델을 “겸손하지만 실질적인 개선”이라고 표현했습니다. 혁신적 도약이 아니라 4.7의 약점을 다듬은 버전이라는 뜻입니다. 출시 전 떠돌던 기대치는 Opus 4.8 사전 유출 정리에서 다룬 적이 있는데 실제 결과는 그보다 차분합니다.
Claude Opus 4.8, 지금 써야 할까
결론을 정리하면 이렇습니다. 코딩과 에이전트 작업을 많이 하고 AI의 거짓 보고에 데어본 분이라면 4.8을 분명한 업그레이드로 체감할 겁니다. 정직성 개선이 실무 신뢰도를 직접 끌어올리기 때문입니다.
반대로 단순 글쓰기나 가벼운 작업만 한다면 굳이 최상위 모델이 필요 없습니다. 더 싼 Sonnet 계열로도 충분합니다. 모델을 용도별로 나눠 쓰는 게 비용 면에서 합리적입니다.
진짜 도약은 다음 등급 모델인 Mythos를 기다리는 분위기입니다. 그 전까지 코딩 현업의 현실적 최선은 4.8이라는 데 큰 이견은 없어 보입니다.
자주 묻는 질문
Q. Claude Opus 4.8은 정말 거짓말을 안 하나요?
거짓말이 완전히 사라진 것은 아닙니다. Faros AI 분석 기준 존재하지 않는 진행 상황을 보고하는 행동이 4.7 대비 약 4배에서 10배 줄었습니다. “0”이 아니라 “대폭 감소”로 이해하는 것이 정확하며 여전히 사용자의 검토는 필요합니다.
Q. Opus 4.8 환각은 이전보다 줄었나요?
평가가 엇갈립니다. 앤트로픽은 사실 환각을 줄이도록 학습했다고 밝혔습니다. 반면 일부 실사용자는 4.7과 차이를 못 느꼈다고 합니다. MCP 도구 사용 시 환각을 더 봤다는 보고도 있습니다. 줄긴 했으나 극적인 개선은 아니라는 평가가 우세합니다.
Q. Opus 4.8 가격은 4.7보다 비싸졌나요?
기본 가격은 동일합니다. 입력 100만 토큰당 5달러, 출력 100만 토큰당 25달러로 4.7과 같습니다. 오히려 Fast Mode 단가는 입력 30달러에서 10달러, 출력 150달러에서 50달러로 약 3배 내려갔습니다.
Q. Opus 4.8 USAMO 점수는 어떤 의미인가요?
USAMO 2026에서 96.7%를 기록해 4.7의 69.3%를 크게 앞섰습니다. 이 대회가 모델 학습 종료 이후 열려 답을 미리 외울 수 없었다는 점에서 순수 추론 능력을 보여주는 지표로 평가됩니다.
Q. Opus 4.8과 GPT 5.5 중 코딩에는 뭐가 낫나요?
작업에 따라 다릅니다. SWE-Bench Pro 같은 까다로운 코딩 벤치마크에서는 Opus 4.8이 GPT 5.5를 약 10포인트 앞섰습니다. 다만 일부 종합 코딩 지표에서는 GPT 5.5의 최고 설정이 근소하게 앞서기도 합니다.
📺 출처: Two Minute Papers — “Claude Opus 4.8: Lying Machine No More?”
Claude Opus 4.8은 점수표를 화려하게 갈아치운 모델은 아닙니다. 대신 AI에게 가장 아쉬웠던 부분, 솔직함을 채운 모델입니다. 거짓 보고에 시간을 빼앗겨본 코딩 사용자라면 이 변화의 값어치를 가장 크게 체감할 겁니다.